はじめに
以下で記事に書いたアプリで文字起こしにGoogle Cloud Speech to Text v1を使っています。
それをv2に変更したので備忘録です。

コードは以下にあります。

はじめに
権限
v1のときはAPIキーだけあれば使えましたが、v2では明確に作成したサービスアカウントにCloud Speech クライアントのロールを割り振る必要があります。
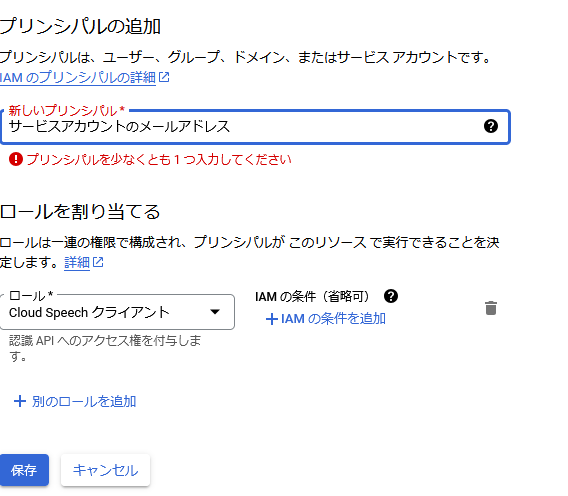
IAM > アクセスを許可 と移動します。
表示されるポップアップに以下のように入力してロールを割り当ててください。
「サービスアカウントのメールアドレス」はサービスアカウントのページに行けば確認できます。
コードの修正
インポートするのはfrom google.cloud import speech_v2に変更します。
まず大きく変わるのはStreamingRecognitionConfigの引数です。
self.streaming_config = speech_v2.types.StreamingRecognitionConfig(
config=speech_v2.types.RecognitionConfig(
# 自動で音声を解析する設定があるが、対応していないエンコーディングを使うので使わない
# auto_decoding_config=speech_v2.types.AutoDetectDecodingConfig(),
explicit_decoding_config=speech_v2.types.ExplicitDecodingConfig(
encoding=speech_v2.types.ExplicitDecodingConfig.AudioEncoding.LINEAR16,
sample_rate_hertz=16000,
audio_channel_count=1
),
language_codes=["ja-JP"],
model="latest_long",
),
streaming_features=speech_v2.types.StreamingRecognitionFeatures(
interim_results=True
)
)v2では音声のエンコーディングやサンプルレートなどを自動で判別する機能があります。
以下ドキュメントに書かれている形式でエンコードされている場合はauto_decoding_config=speech_v2.types.AutoDetectDecodingConfig() で自動で識別してくれます。
今回はここに書かれていない形式でエンコードしているためexplicit_decoding_configで細かく指定しています。
また、最終結果だけではなく中間結果を受け取りたい場合はstreaming_featuresでinterim_results=Trueを渡す必要があります。
次に大きな変更が必要だったのはStreamingRecognizeRequestです。recognizerというのを最初に渡してあげる必要が出てきました。
config_request = speech_v2.types.StreamingRecognizeRequest(
recognizer=f'projects/{project}/locations/global/recognizers/_',
streaming_config=self.streaming_config
)ここに渡す値はprojects/{project}/locations/{location}/recognizers/{recognizer}という形式の文字列です。
locationは2025/02/10時点ではglobal固定なようです。
recognizerもとりあえず動かしたい場合は_でよさそうです。
projectはGoogle CloudのプロジェクトのIDを指定してください。
感想
v2に変更するにあたって結構コード変える箇所があって大変でした。
公式ドキュメント読むのの練習になったので良いチャレンジでした。
また、Google Cloudの権限回りに苦戦しまして、ここら辺は本当に知識がないので苦しみました。
参考サイトを見つけてからはAWSのIAMに照らし合わせて何となくの理解ができました。
参考にしたサイト
公式ドキュメント
v1 → v2のマイグレーションガイド
v2のリファレンス
v2のサンプルコード

公式以外
権限変更

Follow me!